Como construí meu próprio RAG soberano para análise de segurança de código
| 7 minutes read
Construindo meu próprio RAG soberano para análise de segurança de código
Nos últimos tempos, comecei a olhar com mais atenção para algumas ferramentas de análise de código que prometem identificar falhas de segurança em projetos. A ideia é boa. Recebi uma dessas ferramentas como sugestão e fui atrás para entender melhor o que havia por trás da proposta.
Logo de cara percebi um padrão: os preços dessas plataformas não são exatamente convidativos. Algumas até oferecem planos gratuitos limitados, mas a gente sabe como funciona o jogo. Quando algo muito bom aparece “de graça”, o custo real costuma vir de outro lugar. Coleta de dados, lock-in na plataforma, modelos black-box processando seu código na nuvem de terceiros. E como hoje eu venho estudando bastante IA e, em especial, o tema dos RAGs (Retrieval-Augmented Generation), a pergunta veio automática: por que não montar o meu próprio pipeline, 100% local, soberano, usando ferramentas open-source, rodando direto na minha máquina, sem depender de ninguém?
Assim nasceu o SovereignRAG.
Como funciona
A ideia básica foi simples: alimentar o meu RAG com conhecimento técnico sólido vindo de fontes reconhecidas na área de segurança. Fui direto em materiais como o OWASP Top 10, CWE, NIST e outras referências do setor. A partir daí, montei a seguinte estratégia:
- Coletar as fontes originais em PDF (OWASP Top 10, CWE, NIST, etc).
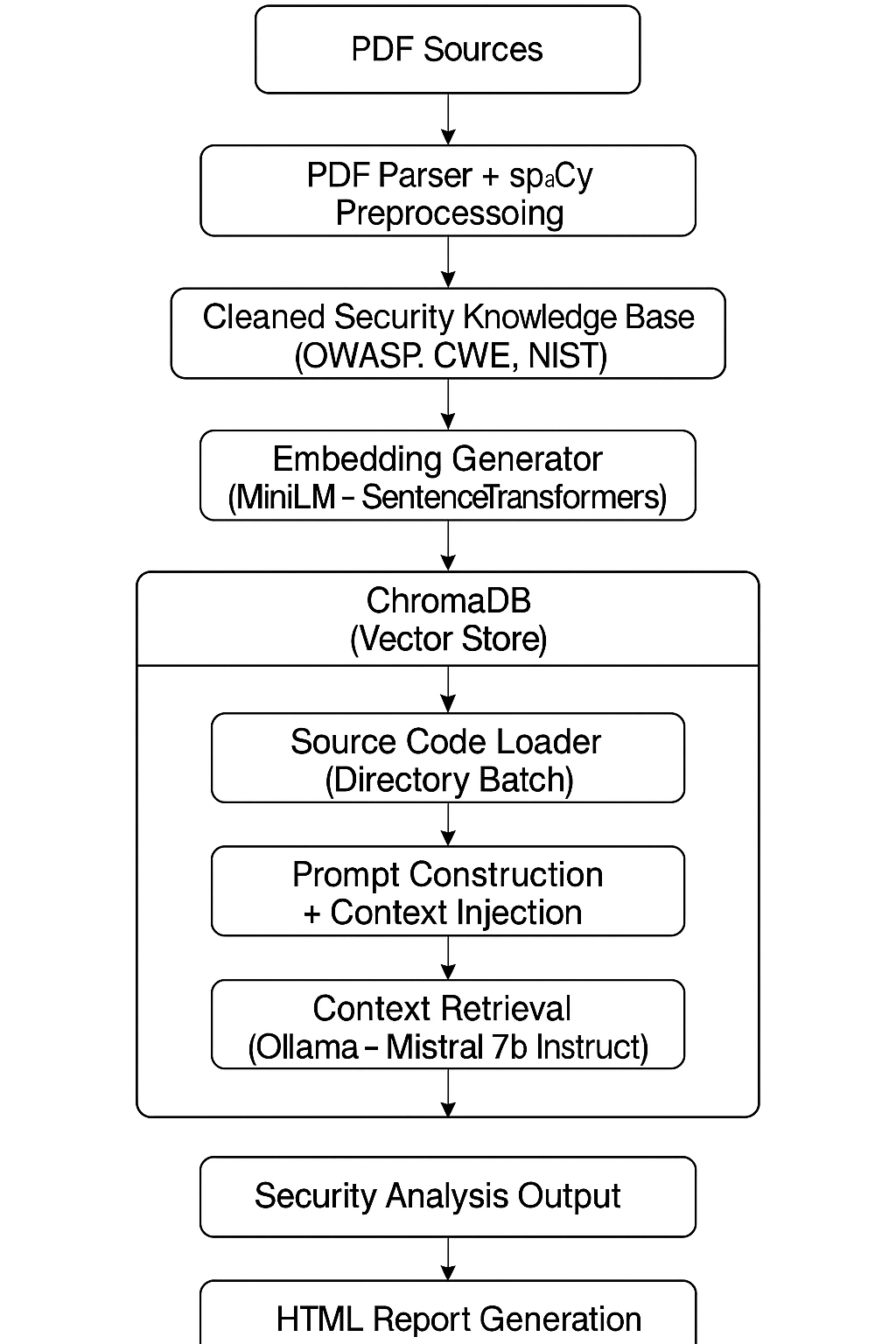
- Criar um parser que faz a extração de texto desses PDFs. Para limpar o material, utilizei NLP com spaCy, removendo ruídos e filtrando o que realmente interessava. O resultado desse processamento foi persistido no ChromaDB como banco vetorial.
- Desenvolver um prompt específico, já hardcoded inicialmente no projeto. O próximo passo natural aqui é tornar esse prompt dinâmico, parametrizável, para deixar a ferramenta mais flexível e adaptável a diferentes contextos.
- Como motor de linguagem, escolhi o Ollama rodando localmente com o modelo mistral:7b-instruct. Não é um modelo gigantesco, mas também não é tão limitado como o phi3-instruct que inicialmente testei. Dentro da limitação de hardware, foi o melhor equilíbrio que encontrei.
Estou rodando tudo isso no meu MacBook Air M1 com 16GB de RAM. É óbvio que o processo não é instantâneo. Inferência de LLM local consome CPU pesado, ainda mais quando começa a trabalhar com inputs longos e contexto técnico denso. Mas o ponto central do experimento foi provado: é perfeitamente viável rodar um pipeline de RAG soberano, offline, mantendo meus dados sob controle total, sem enviar nada para nuvem de ninguém, e principalmente, sem pagar o preço absurdo dessas soluções SaaS “inteligentes” que estão pipocando por aí.
Tenho várias melhorias mapeadas na minha cabeça. Paralelismo não está nos planos por enquanto, justamente porque não pretendo transformar o SSD do meu Mac em carvão swapando como se não houvesse amanhã.
Arquitetura Técnica
Como a ideia sempre foi manter o controle completo do pipeline, a arquitetura do SovereignRAG foi montada de forma modular, com cada etapa bem definida e com ferramentas open-source que eu mesmo pudesse operar localmente. Nada de dependência de serviços externos.
O pipeline ficou assim:
1. Ingestão dos documentos de segurança
A primeira etapa foi coletar e processar a base de conhecimento que alimentaria o RAG. Usei documentos oficiais de segurança no formato PDF, incluindo OWASP Top 10, CWE e NIST. Para extrair o conteúdo relevante, utilizei o PyMuPDF para fazer o parsing dos PDFs e o spaCy para limpeza, tokenização e remoção de informações irrelevantes. Essa etapa é importante porque qualquer ruído desnecessário impacta diretamente a qualidade dos embeddings gerados depois.
2. Embeddings e indexação vetorial
Com o conteúdo limpo em mãos, utilizei o modelo all-MiniLM-L6-v2 do SentenceTransformers para gerar os embeddings. Esses vetores foram armazenados no ChromaDB, um banco de dados vetorial leve e eficiente, que roda tranquilamente em máquina local sem exigir recursos absurdos.
3. Query e análise de código
No modo de análise de código, o pipeline lê o arquivo fonte, injeta o conteúdo no prompt já pré-definido, recupera os documentos mais relevantes do banco vetorial (top_k controlado para não sobrecarregar o modelo) e dispara a inferência.
A inferência roda localmente via Ollama, onde estou utilizando o modelo mistral:7b-instruct. Esse modelo foi o melhor equilíbrio que encontrei entre capacidade de raciocínio, suporte a contexto mais longo e viabilidade de rodar no hardware limitado que estou usando.
4. Geração de relatório
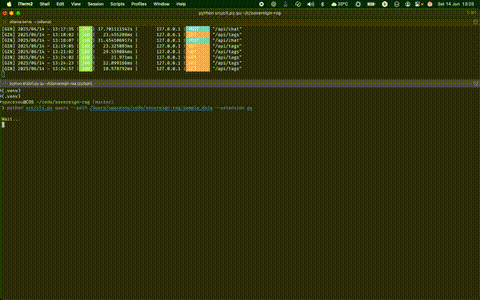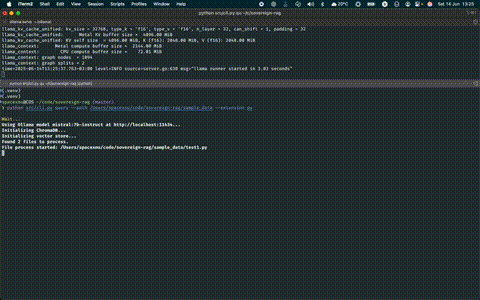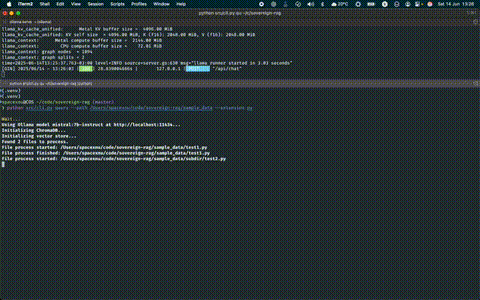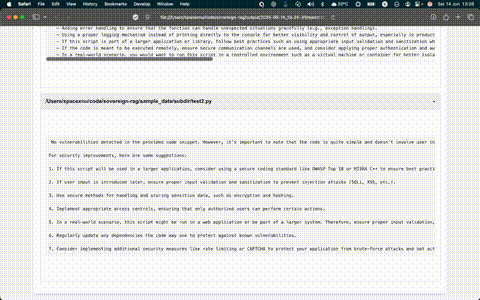
Para não ficar apenas no terminal, decidi gerar relatórios HTML com o resultado da análise de cada arquivo. Assim, além de permitir revisar o output com mais calma, também já abro espaço para no futuro transformar isso numa interface web mais organizada.
Desafios, Limitações e Lições Aprendidas
Obviamente não existe mágica nessa história. Rodar um pipeline de RAG local, offline e soberano, com análise de código em cima de bases complexas de segurança, tem um conjunto bem claro de desafios. Não é o tipo de solução plug-and-play que os SaaS vendem, e também não é para qualquer perfil técnico.
O primeiro ponto que bate logo de cara é o próprio hardware. Rodar LLMs exige processamento pesado. Estou rodando tudo isso num MacBook Air M1 com 16GB de RAM, que é uma máquina excelente para muita coisa, mas está longe de ser um equipamento desenhado para processamento de inferência de IA em larga escala. Isso me forçou a tomar decisões bem pragmáticas desde o início: processamento serial (um arquivo por vez), controle rígido sobre o tamanho do contexto (top_k ajustado com cautela), chunking agressivo nos documentos durante a ingestão, e claro, nada de paralelismo. Paralelizar nesse contexto seria simplesmente suicídio térmico e desgaste desnecessário do SSD swapando sem parar.
Outro desafio importante é o próprio comportamento dos LLMs quando recebem contexto técnico muito denso. Aprendi rápido que não adianta simplesmente injetar documentação inteira e esperar que o modelo resolva tudo sozinho. Existe um trabalho delicado de engenharia de prompt aqui, para guiar o modelo na direção certa sem sobrecarregar o raciocínio dele com ruído desnecessário.
Além disso, o próprio balanceamento entre embedding de qualidade e performance de inferência local é um ponto que exige testes práticos. O modelo MiniLM foi uma boa escolha inicial para gerar embeddings compactos e eficientes, mas já vejo espaço para experimentar embeddings ainda mais otimizados no futuro (BGE, Instructor, etc).
Por fim, o mais óbvio de todos: velocidade. Não tem como rodar isso localmente e esperar tempos de resposta instantâneos, ainda mais com modelos de 7B. A cada análise, é preciso ter um pouco de paciência. Não é o tipo de ferramenta para integrar num fluxo de CI/CD ainda, mas como laboratório e prova de conceito soberano, cumpre o seu papel com excelência.
Próximos passos e evolução do projeto
O SovereignRAG nasceu como um laboratório, mas já começa a apontar caminhos interessantes para expansão. A arquitetura atual é funcional e cumpre bem o propósito de validar o conceito de RAG soberano aplicado à segurança de código, mas existem várias camadas de melhorias que pretendo implementar nas próximas etapas.
O primeiro ponto da lista é refinar ainda mais o chunking durante a ingestão dos documentos. Esse é um dos fatores mais críticos na construção de qualquer pipeline de RAG. Chunk errado, contexto errado. Existe um trabalho fino aqui para encontrar o melhor equilíbrio entre granularidade dos chunks, qualidade dos embeddings e capacidade de recall do vector store.
Outro ponto natural de evolução está nos próprios embeddings. Hoje estou usando o all-MiniLM-L6-v2 por uma questão de leveza e viabilidade no meu ambiente atual, mas já estou de olho em modelos mais sofisticados como o BGE e o Instructor, que podem oferecer embeddings semanticamente mais precisos para o tipo de dado que estou trabalhando.
Do lado da inferência, há espaço para experimentar outros modelos além do mistral:7b-instruct. Eventualmente posso validar o Mixtral ou até mesmo trabalhar com quantizações otimizadas que permitam melhorar a performance no hardware limitado. Também não descarto no futuro montar um pequeno servidor soberano dedicado só para rodar esse tipo de workload de forma mais fluida, preservando o MacBook para as tarefas de desenvolvimento e produção de conteúdo.
Outro objetivo de curto prazo é tornar o pipeline um pouco mais flexível e parametrizável. Hoje o prompt está hardcoded dentro do código. A ideia é abrir essa configuração, permitir ajustes mais fáceis, talvez até implementar templates de análise para diferentes tipos de projeto ou linguagem.
Por fim, o grande movimento de médio prazo envolve transformar o que hoje é um laboratório em um produto real. O SovereignRAG já serve de embrião para o que pode vir a ser o CodeTalon, um produto fechado, profissional, preparado para atuar em ambientes de segurança corporativa com análise de código soberana, offline e privada, sem depender de APIs de terceiros, nuvens obscuras ou SaaS engessados.
O conceito está plantado. Agora é seguir no aprimoramento técnico e deixar a máquina cada vez mais afiada.